
はじめに
PostgreSQLを勉強するにあたって、構築や運用で必要そうな事を備忘として記事にしました。
本記事は、プランナが作成する実行計画について確認していきます。
前提
PostgreSQL 13 を使用しています。
実行計画について
PostgreSQLに対して問い合わせ(クエリ)を発行すると、PostgreSQLのプランナは様々な検索方法の中から処理コストが最小となる組み合わせを計算します。この最小化された検索方法のことを「実行計画」といいます。
PostgreSQLが算出した実行計画は、必ずしも最適なものとは限りません。そのため各種チューニングが必要となるケースがあります。
実行計画の確認
EXPLAIN オプション
実行計画は、SQLにEXPLAINを付与することで内容を確認することができます。実際にSQLは発行されず、表示される情報も推測値となります。
EXPLAIN SQL文;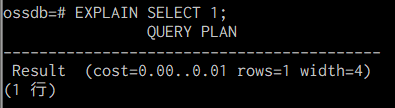
図. EXPLAINの実行 (テスト実行)
EXPLAIN ANALYZE オプション
EXPLAIN ANALYZEを付与した場合は、実際にSQLが実行され、実行計画と実行処理時間の両方を取得します。PostgreSQLでは、明示的にトランザクションを開始していない限りデータ更新は自動でコミットされます。実データに影響を与えないようにするために、トランザクションを開始(BEGIN)し、EXPLAIN ANALYZEでの実行後、ロールバック(ROLLBACK)することで安全に実行できます。
EXPLAIN ANALYZE SQL文;
図. EXPLAIN ANALYZEの実行 (本番実行)

図. ロールバック前提のEXPLAIN ANALYZE
VERBOSE オプション
実行計画の各ノードが出力する列名の情報を追加で出力します。
EXPLAIN VERBOSE SQL文;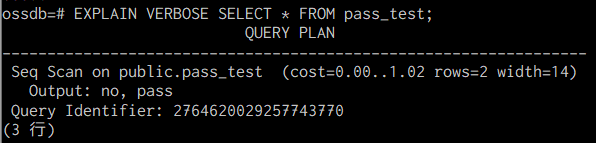
図. EXPLAIN VERBOSE
FORMAT オプション
EXPLAIN文の出力フォーマットを指定します。デフォルトは「TEXT形式」です。他には「XML形式」、「JSON形式」、「YAML形式」があります。
EXPLAIN (FORMAT yaml) SQL文;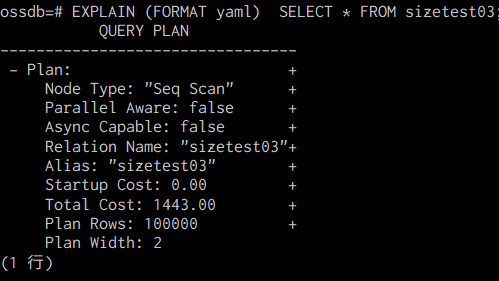
図. EXPLAIN FORMAT指定
実行計画の見方
実行計画では処理する単位を「ノード」と呼びます。ノードは階層構造を持ち、テキスト形式で表示される場合は、1行目に最上位ノード、順に「->」の記号とインデントにより複数のノードが表現されます。基本的に問い合わせの実行は、もっとも深い階層のノードから順番に実行され、最上位のノードは一番最後に実行されます。
親ノードのコストは子ノードのコストを含んだ形で表示されることになります。最初の1行目(最上位ノード)には、計画全体の実行コストの推定値が含まれます。プランナはこの値が最小値となるように動作します。

図. 実行結果
表. 実行計画の主な表示項目
| 項目 | 説明 |
|---|---|
| Result | プランタイプ エグゼキュータが実際にデータを処理するための具体的な手順 |
| cost | 左側の値(0.00)・・・最初の行を取得するまでのコスト プランナコスト定数と統計情報を基に算出された想定値で、相対値 ※実行時間でとは異なる 右側の値(0.01)・・・すべての行を取得するまでのコスト |
| rows | 統計情報を基に推測される取得行数 |
| width | 統計情報を基に推測される1行当たりのサイズ (バイト単位) |
| actual time | 該当情報の1回当たりの平均時間 |
| loops | ループ回数 |
| Planning Time | 計画の作成時間 |
| Execution Time | 実行時間 |
確認ポイント
コストは相対的な値であるため、実行時間と比較しても意味がありません。「各子ノードのコスト」が「計画全体のコスト」に占める割合と「各子ノードの実行時間」が「全体の実行時間」に占める割合を比較し、乖離している箇所がないかを確認します。
乖離している場合、プランナコスト定数が正しく設定されていないか、統計情報が正しく集計されていない可能性があります。
ノード
ノードを「スキャン」「複数のデータを結合」「データを加工」の3つに分類し、代表的なものを上げます。
スキャンノード
表. スキャンノード
| ノード名 | 説明 |
|---|---|
| Seq Scan | テーブル全体を順番にスキャンする |
| Index Scan | テーブルに付与されたインデックス順にテーブルをスキャンする |
| Index Only Scan | テーブルに付与されたインデックスだけを使用してスキャンする |
| Bitmap Scan | テーブルに付与されたインデックスからビットマップを作成して テーブルをスキャンする |
| Foreign | 外部表に対してスキャンする |
| Function Scan | 組み込み関数やユーザ定義関数を実行する |
結合ノード
表. 結合ノード
| ノード名 | 説明 |
|---|---|
| Seq Scan | 外側テーブルの1行のデータに対して、内側テーブルをすべて評価する |
| Hash Join | 作成した内側テーブルのハッシュに基づいて外側テーブルを評価する |
| Merge Join | 結合条件でソートされたテーブルを順に評価する |
データを加工するノード
表. データを加工するノード
| ノード名 | 説明 |
|---|---|
| Sort | スキャン結果をソートする |
| Hash | スキャン結果からハッシュを作成する |
| Aggregate | スキャン結果をsum()やavg()などの特定の演算で集約する |
| HashAggregate | スキャン結果からハッシュを作成しその結果から集約する |
| Append | スキャン結果に別のスキャン結果を追加する |
| BitmapOr | 複数のビットマップスキャン結果の和(OR)を取得する |
| Modify Table | INSERT/UPDATE/DELETEなどの更新系SQLに EXPLAINを発行した時の特殊なノード |
| Materialize | スキャン結果を一時的にファイルを書き出す |
| Gather | 並列に実行したスキャン結果を集約する |
各パラメータ
処理コストの見積もりのためのパラメータ
始動コスト、総コストはノードごとの計算式が存在します。計算式に利用するコスト調整パラメータを変更することでコスト見積もりをチューニングできます。
表. 設定ファイルのコスト調整パラメータ
| ノード名 | 初期値 | 説明 |
|---|---|---|
| seq_page_cost | 1 | ディスクをシーケンシャルアクセスする時に1ページ分(8KB)を 読み込むためのコスト値 |
| random_page_cost | 4 | ディスクをランダムアクセスする時に1ページ分(8KB)を 読み込むためのコスト値 |
| cpu_tuple_cost | 0.01 | テーブルの1行の処理にかかるCPUコスト |
| cpu_index_tuple_cost | 0.005 | インデックススキャンで1回の処理にかかるCPUコスト |
| cpu_operator_cost | 0.0025 | 演算1回の処理にかかるCPUコスト |
| effective_cache_size | 4GB | ディスクアクセス時のキャッシュヒット率を予想するために 用いる値。PostgreSQLが利用している過程できるメモリサイズ を設定する |
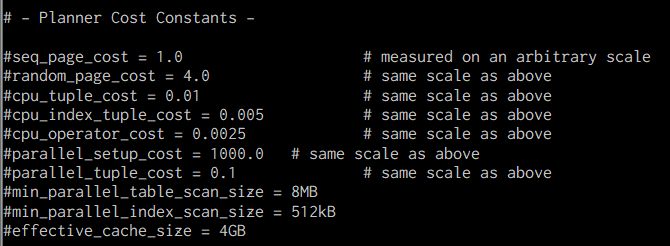
図. コスト調整パラメータ
統計情報取得のためのパラメータ
表. 統計情報の精度に関するパラメータ
| パラメータ | デフォルト値 | 説明 | 設定 |
|---|---|---|---|
| autovacuum | on | 統計情報を自動で収集するか。 自動で収取する場合は、「off」 | postgresql.conf CREATE TABLE ALTER TABLE |
| autovacuum_vacuum_ threshold | 50 | 更新されたテーブルの行数が 指定値未満の場合、統計情報は自動で 更新されない | postgresql.conf CREATE TABLE ALTER TABLE |
| autovacuum_analyze_ scale_factor | 0.1 | 更新されたテーブルの行数が指定割合未満 の場合、統計情報は自動で更新されない。 デフォルト値(0.1)は10%未満を意味する | postgresql.conf CREATE TABLE ALTER TABLE |
| default_statistics _target | 100 | 統計情報のサンプリング数。 サンプリング対象は「設定値×300行」 | postgresql.conf ALTER TABLE |
関連記事一覧
PostgreSQL : 実行計画「最適な実行計画が選ばれないケース」
参考文献
1. 勝俣 智成, 佐伯 昌樹, 原田 登志 (2018)「[改訂新版]内部構造から学ぶPostgreSQL 設計・運用計画の鉄則」技術評論社
2. 河原 翔 (2014)「LPI-Japan OSS-DB Gold 認定教材 PostgreSQL 高度技術者育成テキスト」エヌ・ティ・ティ・ソフトウェア株式会社
3. OSS-DB道場